The Future of Search
December 22, 2022
I recently came across DKB IO’s post called Google Search is Dying on
Hacker News. It’s definitely good food for thought, and really gets at some of
the problems that make search a difficult space. In particular, the post brings
up how people often search for things in Google by adding reddit
to the end of
their search queries. They may also append amazon,
stackoverflow,
or
stackexchange
depending on what they’re searching for.
Google as a forum search
Once we dig a little deeper, it makes sense why people are doing this. There are essentially three categories of search queries.
- Facts: examples are “temperature outside,” “NFL scores,” “height of Michael Jordan,” etc. In other words, queries that have a clear 1:1 query and answer. Google is amazing at these.
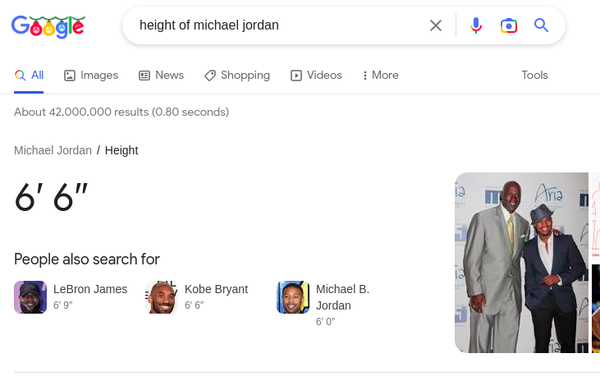
- Objective information: examples are “George Washington,” “Nelson Mandela,” “The Seven Years War,” etc. These are queries that have objective information attached to them. Usually for these types of queries the Wikipedia link is a good starting point, and the user might have to jump to the external links inside to get some in depth information. In many cases, Google will also present other information about these queries in the other search results, but these are “low trust” results, or worse versions of Wikipedia such as Britannica. They have a lot of ads, they are possibly unmaintained, and they have questionable veracity.
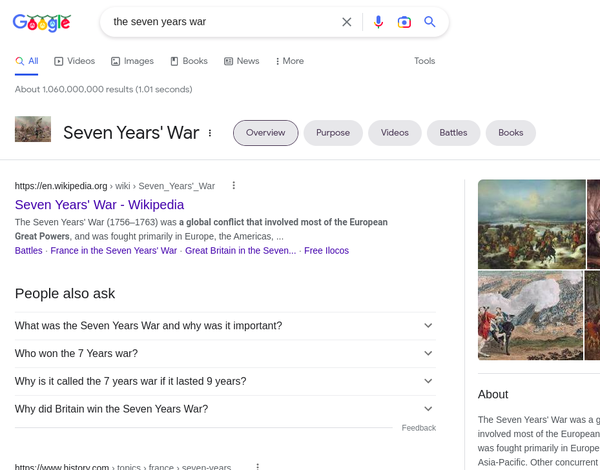
the seven years warthe top hit you get is Wikipedia.
- Subjective information: examples are “What’s the best programming language,” “how to get into Harvard,” etc. These are queries which are handled even worse by Google. And, these are the queries that people often append “reddit” for. They do this, because that will lead to a place where the topic is discussed, multiple inputs are provided, and there is feedback on those inputs so that you can judge all of the info before making a decision.
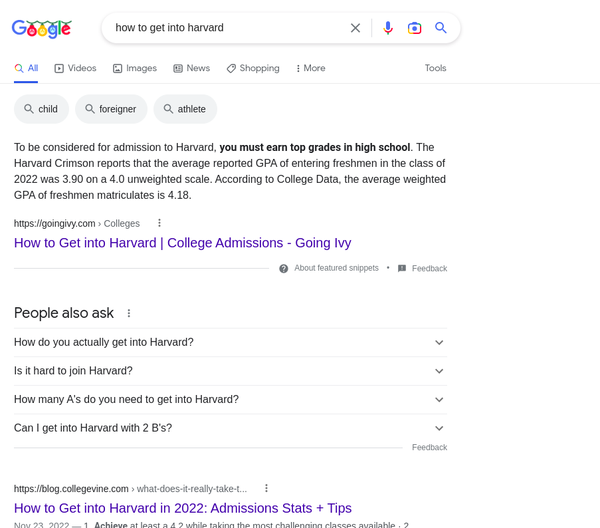
how to get into harvardyields subpar results compared to the previous two. goingivy.com is a blog post to advertise for the company's consulting services. People would usually prefer information from former students and parents, hence they may try appending
collegeconfidential.
Ultimately, if there is no authoritative source on a matter, people want a democratic answer, hence the desire to search on a forum. If there’s no factual result, they want to see a discussion involving real people so they can weigh the many sides of an argument themselves. Google is heavily optimized for the first category of queries, and partly optimized for the second category of queries. The third set usually surfaces untrustworthy results, such as random blog posts, or SEO spam sites.
If Reddit, StackOverflow, and other forums have the information that people are really looking for, why do people still use Google? Unlike Google, all of these disparate forum sites have lackluster search. Google unsurprisingly has best-in-class search.
Democratized information
Implicitly, people are looking for expert opinions on topics. They want to solicit the thoughts of someone who has already looked into it, and let other people give their thoughts. Of course they could pose their own question on a forum, but that would take time for the question to be answered (if it is even popular). Forum search also accounts for the long tail of information. Information that is sufficiently niche that Google cannot serve anything useful or trustworthy. For example, if you search for “Guliga daiva” after watching Kantara (extremely niche subject), you get a bunch of surface level news articles and blog posts. There is nothing authoritative or democratic.
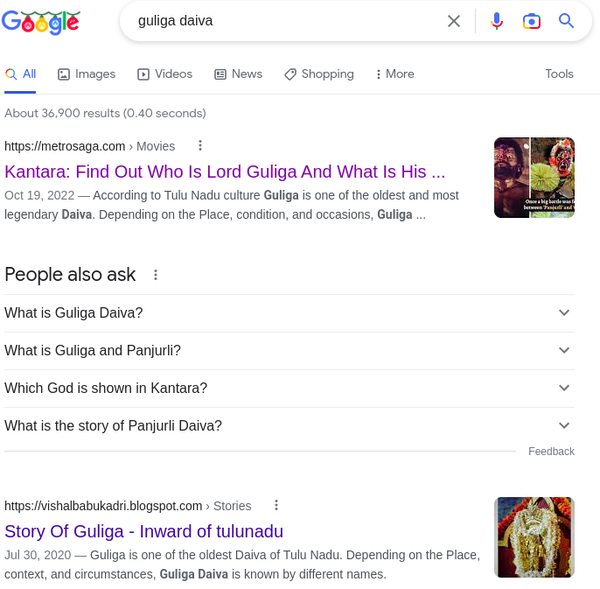
guliga daivajust leads you to some obscure blogs.
Recently, there have been great strides in large language models. ChatGPT has gone viral. If what people really want is an expert opinion on topics, why can’t we make a ChatGPT for all of the “experts” we trust? For example, if you want to know what Mahatma Gandhi would think about the “antifa” riots, we could fine tune a ChatGPT style LLM on Gandhi’s writings and sayings, and generate something plausible.
However, the main issue that we currently see with ChatGPT and others is that they struggle with surfacing actual facts. For example, if you have never read William Faulkner’s Absalom, Absalom! then you would not be able to tell that while ChatGPT’s synopsis of the novel sounds plausible, it’s actually inaccurate. Thomas Sutpen does have a son named Henry, but Quentin is not his grandson. He is the narrator of the story and belongs to the Compson family.

Explainable AIs
Solving the accuracy problem is the main issue that prevents us from using LLMs for information retrieval. Some models such as GopherCite, WebGPT, and LaMDA attempt to do this by essentially composing the answers by augmenting the response with search engine results. However, if people do not trust many search results for most opinionated topics, then using search results to provide post facto justification for the responses would not give users any confidence.
Instead what we really want is to have an explainable AI that can cite how it arrived an answer using the resources that were used to train it. This would hit several birds with one stone. It would give users confidence that the training was used with data that did not violate anyone’s privacy, that the data is from trustworthy sources, and that the response was formed sensibly. Obviously this is an extremely hard problem to solve, but it’s absolutely essential for us to be able to use LLMs widely.
As A Survey of the State of Explainable AI for Natural Language Processing (arXiv:2010.00711) explains, we are looking for a global self-explaining model. Many explainable language models are local, meaning they explain what parts of your input were most important. What we care about is global explainability, which means we want an explanation of the output regardless of the input. We want an explanation based on what the model actually learned.
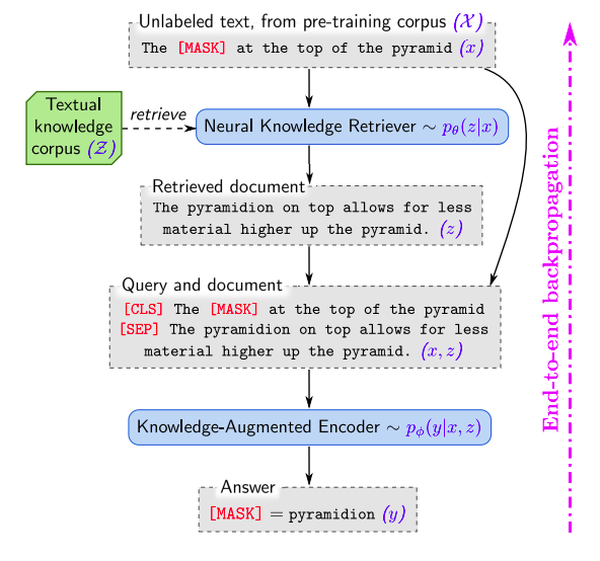
One interesting approach is REALM, which trains a knowledge retrieval model that sits in front of a masked language model. The knowledge retrieval model provides documents that can be used to fill in the masked tokens in the language model’s response. Because the knowledge retrieval model is essentially a function that given a query and a document generates a relevance score, we can use the model to interpret which documents were used to inform the response you received. Breaking down the documents into paragraphs or sections could also help us rate the relevance of each part of a document.
Parting thoughts
No matter how well an LLM can formulate answers, or how well it’s able to explain its answers, many humans will always prefer to see the thoughts and opinions of real people. But, LLMs can help you summarize long threads, and cite the most important comments in a thread.
There is also a long tail of information buried in sources that are extremely hard to surface through regular Google search results. Often, if you have an obscure topic, you can try looking up the information in Google Books. For example, we could try looking up Guliga daiva:
Guliga daiva.
These searches will often surface some high quality sources, but you might have to do quite a bit of reading to get the information you’re looking for. The same is true for scientific topics where relevant answers are only in dense research papers. An LLM that explains itself can be used to present the user with the paragraphs in books, papers, and long forum threads that are most relevant, along with an easy to understand summarization. In short, LLMs will not replace search, but will help to create a more useful interface for search.
Let me know what you think about this article by leaving a comment below, reaching out to me on Twitter or sending me an email at pkukkapalli@gmail.com